Créer un dictionnaire français pour KeepassXC
Sommaire
Dans un post précédent je vous expliquais comment ajouter un dictionnaire français à KeepassXC quand on utilise sa version AppImage. Mais d’abord, où trouver un tel dictionnaire ? Une occasion de jouer avec la puissance des expressions régulières.
Retour aux sources
Il existe de nombreuse listes de mots disponible en ligne. Néanmoins dans cet article je souhaite vous présenter une manière simple de générer sa propre liste à partir d’une source fiable. Pour cela je pars de l’extension dictionnaire français de LibreOffice1 dont on peut supposer qu’elle offre une bonne base de départ. On commence donc par télécharger cette extension et en extraire un des dictionnaires, après avoir vérifié que sa licence nous laisse le droit d’y effectuer des modifications — c’est pour ça qu’on aime le logiciel libre.
test@test:~$ mkdir dictionnaire
test@test:~$ cd dictionnaire/
test@test:~/dictionnaire$ wget https://extensions.libreoffice.org/assets/downloads/z/lo-oo-ressources-linguistiques-fr-v5-7.oxt
--2022-01-30 16:01:56-- https://extensions.libreoffice.org/assets/downloads/z/lo-oo-ressources-linguistiques-fr-v5-7.oxt
Résolution de extensions.libreoffice.org (extensions.libreoffice.org)… 89.238.68.135, 2a00:1828:a012:135::1
Connexion à extensions.libreoffice.org (extensions.libreoffice.org)|89.238.68.135|:443… connecté.
requête HTTP transmise, en attente de la réponse… 200 OK
Taille : 3419712 (3,3M) [application/vnd.openofficeorg.extension]
Sauvegarde en : « lo-oo-ressources-linguistiques-fr-v5-7.oxt »
lo-oo-ressources-linguistiques-fr-v5-7.oxt.1 100%[=================================================================================================>] 3,26M 339KB/s ds 13s
2022-01-30 16:02:09 (265 KB/s) — « lo-oo-ressources-linguistiques-fr-v5-7.oxt » sauvegardé [3419712/3419712]
test@test:~/dictionnaire$ unzip lo-oo-ressources-linguistiques-fr-v5-7.oxt
Archive: lo-oo-ressources-linguistiques-fr-v5-7.oxt
inflating: description.xml
inflating: dictionaries/fr-classique.aff
inflating: dictionaries/fr-classique.dic
inflating: dictionaries/fr-moderne.aff
inflating: dictionaries/fr-moderne.dic
inflating: dictionaries/fr-reforme1990.aff
inflating: dictionaries/fr-reforme1990.dic
inflating: dictionaries/fr-toutesvariantes.aff
inflating: dictionaries/fr-toutesvariantes.dic
inflating: dictionaries/frhyph.tex
inflating: dictionaries/hyph-fr.tex
inflating: dictionaries/hyph_fr.dic
inflating: dictionaries/hyph_fr.iso8859-1.dic
inflating: dictionaries/README_dict_fr.txt
inflating: dictionaries/README_hyph_fr-2.9.txt
inflating: dictionaries/README_hyph_fr-3.0.txt
inflating: dictionaries/README_thes_fr.txt
inflating: dictionaries/thes_fr.dat
inflating: dictionaries/thes_fr.idx
inflating: dictionaries.xcu
inflating: DictionarySwitcher.py
inflating: french_flag.png
inflating: META-INF/manifest.xml
inflating: package-description.txt
inflating: pythonpath/ds_strings.py
inflating: ui/addons.xcu
inflating: ui/french_flag_16.bmp
On voit suite à la commande unzip ci-dessus que les dictionnaires sont dans le dossier dictionnaries avec par exemple fr-moderne.dic pour le français moderne.
Choisir ce que l’on veut utiliser
En l’état actuel pourtant ce dictionnaire est inutilisable dans KeepassXC :
-
Il n’est pas au bon format (un mot par ligne et rien d’autre). Par exemple voici les 20 premières lignes du fichier
fr-moderne.dictest@tes:~/dictionnaire$ head -n 20 dictionaries/fr-moderne.dic 77778 & 163 1er/23 154 1ers/23 135 1re/23 180 1res/23 201 1ʳᵉ/23 180 1ʳᵉˢ/23 201 1ᵉʳ/23 154 1ᵉʳˢ/23 135 2CV 100 2D 22 2D 19 2e/23 68 2es 136 2ᵉ/23 68 2ᵉˢ 136 3D 22 3D 19 3e/23 68 -
le dictionnaire contient un tas de caractères spéciaux qui ne sont pas forcément souhaitables. Devoir taper des chose telle que « 1ʳᵉˢ » n’est pas évident voire impossible dans certain contexte. Si l’on souhaite utiliser le dictionnaire pour des utilisateurs lambda, d’après mon expérience les caractères spéciaux ajoutent une grande confusion. Mieux vaux s’en tenir aux caractères acsii.
-
Si l’on doit utiliser plusieurs mots pour former un mot de passe on doit s’assurer que ces mots ne soit ni trop court (trop facile à découvrir lettre par lettre) ni trop long (trop chiant à taper)
Virer tout le reste
Voici un exercice intéressant de réécriture de fichier au moyen d’expressions régulières : il y a 77778 lignes dans le dictionnaire et l’on ne va donc pas s’amuser à les corriger une à une ! Comme il s’agit d’un traitement ligne à ligne on peux utiliser l’outil sed pour traiter le fichier selon ce que l’on souhaite obtenir.
- Commençons par le format du fichier. Si l’on observe le contenu du fichier on constate d’une part qu’il est composé de 2 types de lignes :
| 1 | 2 | 3 | 4 |
|---|---|---|---|
| nom | nombre | caractère tablulation | nombre |
| nom | caractère tablulation | nombre |
D’autre part, la première ligne indique le nombre d’entrées du dictionnaire ce qui ne nous intéresse pas. On supprime cette première ligne avec tail et les éléments superflus avec sed
test@test:~$ tail -n +2 dictionaries/fr-moderne.dic | sed 's#^\([^/\t]*\)\(/[[:digit:]]*\)\?\t[[:digit:]]*$#\1#g' > mon-dico-formaté.dic
tail renvoie la fin du fichier à partir de la ligne 2, pas de grand mystère ici. Le résultat est envoyé à sed et là…
C’est le drame :)
Pas de panique ! Décomposons pour plus d’explique :
| s | # | ^ | \( | [^/\t]* | \) | \( | /[[:digit:]]* | \) | \? | \t[[:digit:]]* | $ | # | \1 | # | g |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| opération de substitution | caractère de délimitation ici commence l’expression que sed doit remplacer | Au début de la ligne | Première expression entre parenthèse (échappées par \) | sélectionne toute suite de caractère ne contenant ni tabulation ni / | on referme la parenthèse échappée | on en ouvre une deuxième | sélectionne toute suite de caractère commençant par / suivie d’une suite de chiffres | On referme la deuxième parenthèse | indique que le groupe entre parenthèse précédant est optionnel | sélectionne une tabulation suivie d’une suite de chiffres | fin de la ligne | caractère de substitution ici commence ce par quoi sed doit remplacer la sélection | désigne la première expression entre parenthèse | caractère de délimitation ici commencent les paramètres supplémentaires pour la substitution | recommence autant de fois que le pattern est trouvé |
-
Voyons maintenant ce que l’on peut faire concernant les caractères non-acsii. On peut déjà lister les caractères concernés.2
test@test:~/dictionnaire$ grep -oP "[\x80-\xFF]" mon-dico-formaté.dic | sort -u ² ³ á à â Å ä ã æ ç é É è È ê ë í î Î ï ñ ó ô ö ù û ü Ü ÿ µ
On peut maintenant définir la façon de les remplacer élégament3. On en profite aussi pour tout convertir en minuscule et retirer les doublons qui pourraient résulter des transformations (commande sort -u).
test@test:~/dictionnaire$ caractere_a_la_con='²³åáàâäãçéèêëíîïñóôöùûüÿµʳᵉˢ'
test@test:~/dictionnaire$ remplacer_par='23aaaaaaceeeeiiinooouuuymres'
test@test:~/dictionnaire$ sed -e 's/\(.*\)/\L\1/' \
-e 'y/'${caractere_a_la_con}'/'${remplacer_par}'/' \
-e 's/æ/ae/g' \
-e 's/œ/oe/g' mon-dico-formaté.dic | sort -u > mon-dico-formaté-acsii.dic
-
Retirer les mots trop longs ou trop courts
Je conserve les mots d’au moins 4 lettres et jusqu’à 7 lettres. Cette fois on va utilisergrepqui accepte également les expressions regulières avec l’interrupteur-Etest@test:~/dictionnaire$ grep -E '^.{4,7}$' mon-dico-formaté-acsii.dic > mon-dico-formaté-acsii-4-à-7-lettres.dic -
Pour finir vérifions combien de mots contient le dictionnaire
test@test:~/dictionnaire$ cat mon-dico-formaté-acsii-4-à-7-lettres.dic | wc -l 20340
Tester dans KeepassXC
Une fois donc notre dictionnaire intégré à KeepassXC, on obtient quelque chose comme ceci :
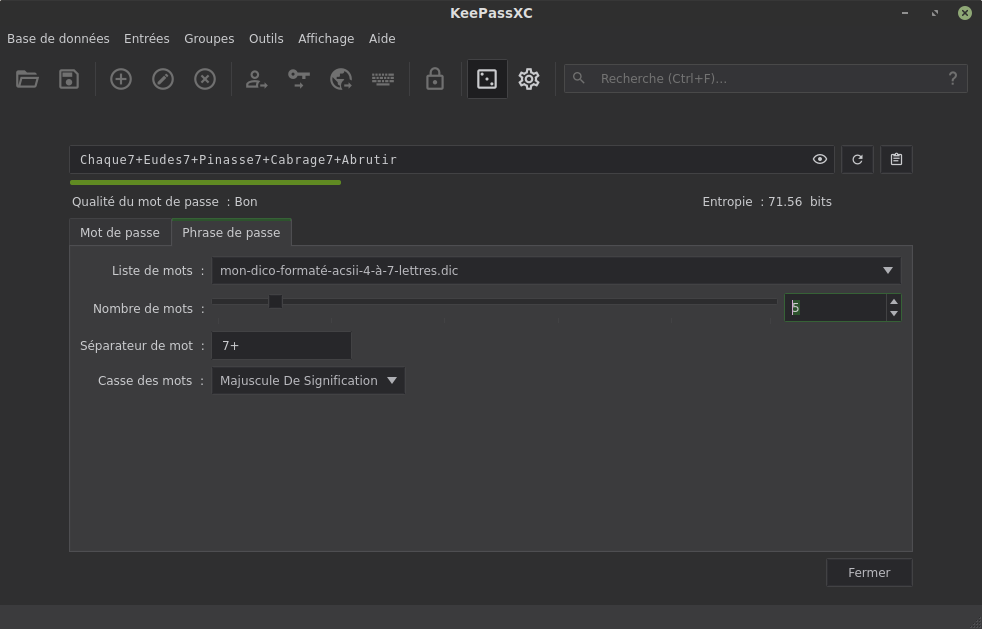
-
Si vous utilisez une distribution avec un environnement de bureau, le dictionnaire sur lequel se base ceux de LibreOffice est probablement déjà installé. Par exemple sous Debian le paquet hunspel-fr installe le fichier
/usr/share/hunspell/fr_FR.dic↩︎ -
Pour une raison que j’ignore les caractères œ ʳ ᵉ ˢ manque à la liste ↩︎